
Uncertainty, Error and Graphs
In physics, as in every other experimental science, one cannot make any measurement without having some degree of uncertainty. A proper experiment must report for each measured quantity both a “best” value and an uncertainty. Thus it is necessary to learn the techniques for estimating them. Although there are powerful formal tools for this, simple methods will suffice in this course. To a large extent, we emphasize a “common sense” approach based on asking ourselves just how much any measured quantity in our experiments could be “off”.
One could say that we occasionally use the concept of “best” value and its “uncertainty” in everyday speech, perhaps without even knowing it. Suppose a friend with a car at Stony Brook needs to pick up someone at JFK airport and doesn't know how far away it is or how long it will take to get there. You might have made this drive yourself (the “experiment”) and “measured” the distance and time, so you might respond, “Oh, it's 50 miles give or take a few, and it will take you one and a half hours give or take a half-hour or so, unless the traffic is awful, and then who knows?” What you'll learn to do in this course is to make such statements in a more precise form about real experimental data that you will collect and analyze.
Semantics: It is better (and easier) to do physics when everyone taking part has the same meaning for each word being used. Words often confused, even by practicing scientists, are “uncertainty” and “error”. We hope that these remarks will help to avoid sloppiness when discussing and reporting experimental uncertainties and the inevitable excuse, “Oh, you know what I mean (or meant).” that attends such sloppiness.
We rarely carry out an experiment by measuring only one quantity. Typically we measure two or more quantities and then “fold” them together in some equation(s), which may come from theory or even be assumed or guessed, to determine some other quantity(ies) that we believe to depend on them. Typically we compare measured result(s) with something – previous measurement(s) or theory(ies) or our assumption(s) or guess(es) – to find out if they do or do not agree. Since we never know exactly results being compared, we never obtain “exact agreement”. If two results being compared differ by less/more than the combined uncertainties (colloquially, the “sum” of their respective uncertainties), we say that they agree/disagree, but the dividing line is fuzzy. Without uncertainties, you can't say anything about agreement or disagreement, which is why uncertainties are so important in experimental science. We say that there is a “discrepancy” between two results when they “disagree” in the above sense.
Though we may assume that some quantity has an exact “true” result, we cannot know it; we can only estimate it. Now think this way about the agreement/disagreement comparison. If both compared values were known exactly, agreement would mean that the difference between them is zero. Since you don't know them exactly, the actual compared difference is never exactly zero. We may summarize this by the simple statement, worth remembering, “You cannot measure zero.” What you can say is that if there is a difference between them, it's less than such-and-such amount. If that amount is less than the combined uncertainty, then we say, “We do not find a discrepancy. The difference between them is consistent with zero.” The difference can never be exactly zero in a real experiment.
A frequent misconception is that the “experimental error” is the difference between our measurement and the accepted “official” value. (Who accepts it? Why? Not just because someone tells you without any evidence why it should be accepted.) What we mean by experimental uncertainty/error is the estimate of the range of values within which the true value of the quantity we're trying to measure is likely to lie. This range is determined from what we know about our lab instruments and methods. It is conventional to choose the uncertainty/error range as that which would comprise 68% of the results if we were to repeat the measurement a very large number of times.
In fact, we seldom make enough repeated measurements to calculate the uncertainty/error precisely, so we are usually given an estimate for this range. Note, however, that the range is established to include most of the likely outcomes, but not all of them. You might think of the process as a wager: pick the range so that if you bet on the outcome being within this range, you will be right about 2/3 of the time. If you underestimate the uncertainty, you will eventually lose money after repeated bets. (Now that's an error you probably don't want to make!) If you overestimate the range, few will be willing to take your bet!
More detail will be found in subsequent sections. There will be footnotes. Hoveroverthese!
The following appears on p. 3 of Permanent Magnets and Magnetism, D.Hadfield, ed., (London, Iliffe Books Ltd, 1962) in its Chap. 1, Introduction and History by E.N. da C. Andrade:
“William Gilbert, whose De Magnete Magneticisque Corporibus et de Magno Magnete Tellure Physiologia Nova, usually known simply as De Magnete, published in 1600, may be said to be the first systematic treatise of experimental physics in the modern sense. Gilbert excelled as an experimenter: he tells the reader (in Latin), `Let whosoever would make the same experiments handle the bodies not heedlessly and clumsily but carefully, skillfully, and deftly; when an experiment fails he should not ignorantly doubt our discoveries, for there is naught in these books that has not been investigated and done again and again by us'.”
We urge you to keep these wise words of Gilbert in mind while preparing for and doing the experiments in this course.
Using similar-looking symbols to mean different things can cause confusion for the reader. Often it's difficult to avoid this entirely, so let's make sure we clarify a situation that occurs from time to time in this document. Let the quantities and indicate some independent experimental variables and a dependent variable. The variable looks similar to the multiplication or “times” symbol , but if you're careful, you'll learn to recognize the difference. The equation for “zee equals ex times wye” in the algebraic style is ; no problem. If for some reason, however, we want to use the “times” symbol between and , the equation is written . Make sure you don't confuse with or, for that matter, with its lower-case version .
Since nearly everyone refers to “Error Analysis” and not “Uncertainty Analysis” in measurement science, we bow to custom and will use “error” even if we really mean “uncertainty”.
If we denote a quantity that is determined in an experiment as , we can call the error . If, for example, represents the length of a book measured with a meter stick we might say the length cm where the “best” (also called “central”) value for the length is 25.1 cm and the error, , is estimated to be 0.1 cm. To repeat, both the best value and its error must be quoted when reporting your experimental results. Note that in this example the best value is given with just three significant figures. Do not write significant figures beyond the first digit of the error on the quantity. Giving more precision than this to a value is misleading and irrelevant. If you're told you're using (way) too many digits, please do not try to use the excuse, “That's what the computer gave.” You're in charge of presenting your results, not the computer!
An error such as that quoted above for the book length is called the absolute error; it has the same units as the quantity itself (cm in the example). Note that if the quantity is multiplied by a constant factor , the absolute error of is
$$\Delta (aX)=a\Delta X\label{constant}$$We will also encounter relative error, defined as the ratio of the error to the best value of the quantity, so that the relative error of X:
$$\Delta_{rel}X= \Large \frac{\Delta X}{X}\label{relative}$$Thus the relative error of the book length is . (If a decimal number is in the range , always write it with the “leading zero”, e.g., 0.004 in the previous sentence.) The relative error is dimensionless, and should be quoted with as many significant figures as are known for the absolute error. Note that if the quantity is multiplied by a constant factor the relative error of is the same as the relative error of ,
$$\Large \frac{\Delta (aX)}{aX}=\frac{\Delta X}{X}$$since the constant factor cancels in the relative error of . Note that quantities with errors assumed to be negligible are treated as constants.
You are probably used to the percentage error from everyday life. The percentage error is the relative error multiplied by 100. In the example above, it is .
Changing from a relative to absolute error:
Often in your experiments you have to change from a relative to an absolute error by multiplying the relative error by the best value,
$$\Delta X=\Large \frac{\Delta X}{X}\normalsize \times X$$Random error occurs because of small, uncorrelated variations in the measurement process. For example, measuring the period of a pendulum with a stopwatch will give different results in repeated trials for one or more reasons. One reason could be that the watch is defective, and its ticks don't come at regular intervals. Let's assume that you have a “good” stopwatch, and this isn't a problem. (How do “you know for certain” that it isn't a problem? Think about this!) A more likely reason would be small differences in your reaction time for hitting the stopwatch button when you start the measurement as the pendulum reaches the end point of its swing and stop the measurement at another end point of the swing. If this error in reaction time is random, the average period over the individual measurements would get closer to the correct value as the number of trials is increased. The correct reported result would begin with the average for this best value,
$$\Large \overline{t}=\frac {\sum t_{i}}{N} $$ and it would end with your estimate of the error (or uncertainty) in this best value. This usually taken as the standard deviation of the measurements. (In practice, because of time limitations we seldom make a very large number of measurements of a quantity in this lab course.) An estimate of the random error for a single measurement is $$\Large \Delta t=\sqrt{\frac {\sum (t_{i}-\overline{t})^2}{N-1}}$$and an estimate for the error of the average is
$$\Large \Delta \overline{t}=\sqrt{\frac {\sum (t_{i}-\overline{t})^2}{N(N-1)}} $$where the sum denoted by the symbol is over the measurements . Note in equation (E.5b) the “bar” over the letter ( is pronounced “tee bar”) indicates that the error refers to the error in the average time . (Each individual measurement has its own error .)
In the case that we only have one measurement but somehow know (from, say, a previous set of measurements) what the error of the average is, we can use this error of the average , , multiplied by as the error of this single measurement (which you see when you divide equation (E.5a) by equation (E.5b).) [this paragraph updated 9/20/12 because of update of Eq. (5a)]
If you don’t have a value for the error of , you must do something! Better than nothing is a “guesstimate” for the likely variation based on your experience with the equipment being used for the measurements. For example, for measurements of the book length with a meter stick marked off in millimeters, you might guess that the random error would be about the size of the smallest division on the meter stick (0.1 cm).
Some sources of uncertainty are not random. For example, if the meter stick that you used to measure the book was warped or stretched, you would never get an accurate value with that instrument. More subtly, the length of your meter stick might vary with temperature and thus be good at the temperature for which it was calibrated, but not others. When using electronic instruments such voltmeters and ammeters, you obviously rely on the proper calibration of these devices. But if the student before you dropped the meter and neglected to tell anyone, there could well be a systematic error for someone unlucky enough to be the one using it the next time. Estimating possible errors due to such systematic effects really depends on your understanding of your apparatus and the skill you have developed for thinking about possible problems. For example if you suspect a meter stick may be miscalibrated, you could compare your instrument with a 'standard' meter, but, of course, you have to think of this possibility yourself and take the trouble to do the comparison. In this course, you should at least consider such systematic effects, but for the most part you will simply make the assumption that the systematic errors are small. However, if you get a value for some quantity that seems rather far off what you expect, you should think about such possible sources more carefully. If an instrument is so broken it doesn't work at all, you would not use it. The difficult situation is when an instrument appears to be ok but, in fact, is not. You could end up trusting a device that you do not know is faulty. This happens all the time.
When it does and you report incorrect results to other scientists, you can't “blame” the meter (or buggy computer program or whatever). If it's your name associated with the results being presented, it's your responsibility to make sure the results are as free from errors as you can make them. It you later discover an error in work that you reported and that you and others missed, it's your responsibility to to make that error known publicly. This why (at least some of) the original authors of scientific papers may submit an “Erratum” to a previous publication of theirs, to alert others to errors they have discovered, after the fact, and need to correct publicly. This is much better than having other scientists publicly question the validity of published results done by others that they have reason to believe are wrong. Occasionally, if authors realize that their work in a published paper was “completely” wrong, they may ask the journal editors to publish a “retraction” of their paper. When scientific fraud is discovered, journal editors can even decide on their own to publish a retraction of fraudulent paper(s) previously published by the journal they edit. This does happen, and in this way “science corrects itself.”
A figure like the one below is often used to make a visual comparison of types of error, and it allows us to introduce additional terminology that is often used (incorrectly!) when discussing measurements. You want to be sure you understand the terminology and use it correctly.
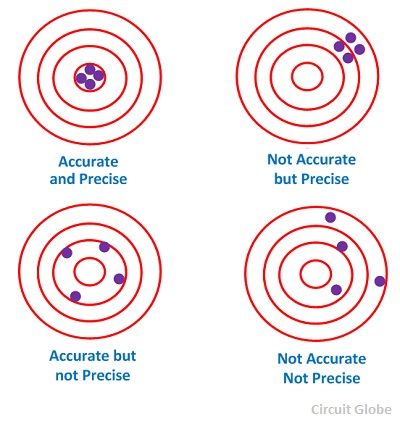
Think of the round object as an archery target. The archer shoots some number of arrows at it, and each dot shows where one landed. Now think of the “bull's eye” – the larger black dot in the center – as the “true” value of some quantity that's being measured, and think of each arrow-dot as a measurement of that quantity. The problem is that the one doing the measurements does not know the “true” value of the quantity; s/he's trying to determine it experimentally, and this means there must be uncertainty associated with the experimentally determined value. Note that each archery target – we'll call them 1,2,3,4 from left to right – shows a different distribution of arrow-hit/measurements.
In number 1 the measurements cluster pretty tightly: we say that the statistical (random) error is small, and the terminology we introduce for that is, “These measurements are precise.” However, the center of their distribution is far from the bull's eye: we say that there is a large systematic error, and the terminology we introduce for that is, “These measurements are not accurate.” In a few words, “These measurements are precise but inaccurate.”
In number 2 the measurements do not cluster tightly, but one can see that the center of their distribution is not far from the bull's eye. These measurements have a large statistical error but a small systematic error. In a few words, “These measurements are imprecise but accurate.”
In number 3 the measurements do not cluster tightly, and one can see that the center of their distribution is not close to the bull's eye. These measurements have a large statistical error and a large systematic error. In a few words, “These measurements are imprecise and inaccurate.”
In number 4 the measurements cluster tightly, and one can see that the center of their distribution is very close to the bull's eye. These measurements have a small statistical error and a small systematic error. In a few words, “These measurements are precise and accurate.”
Here is a crucial point: You can always know your measurements achieve a high level of precision if they cluster tightly, and you can quantify “how precise” they are. But this tells you nothing about how accurate they are. To aim properly, an archer needs to know where the bull's eye is, but suppose, in our analogy, a white sheet is put up to block view of the target. Not knowing where the bull's eye is, the archer's shots could still cluster tightly but there's no way of the archer knowing without additional information where they are with respect to the bull's eye. The accuracy is unknown.
To achieve high experimental accuracy requires that all measuring instruments and all measurement procedures need to be thoroughly understood and calibrated, quantitatively, against relevant “standards”, e.g,, the length standard, the time standard, the voltage standard, etc. The average laboratory, and certainly our undergraduate teaching laboratories, lack such standards. They are expensive to acquire and maintain. Periodically they should be compared with “the” (primary) standards maintained, say, by NIST, the National Institute of Standards and Technology, or by similar organizations in other countries. Section 8 of the U.S. Constitution specifies that is the duty of the Federal Government “To coin Money, regulate the Value thereof, and of foreign Coin, and fix the Standard of Weights and Measures…”. It's not optional; it's the law.
Make sure you now know the difference between “precision” and “accuracy”.
Often in the lab, you need to combine two or more measured quantities, each of which has an error, to get a derived quantity. For example, if you wanted to know the perimeter of a rectangular field and measured the length and width with a tape measure, you would then have to calculate the perimeter, , and would need to get the error of from the errors you estimated for and , and . Similarly, if you wanted to calculate the area of the field, , you would need to know how to do this using and . There are simple rules for calculating errors of such combined, or derived, quantities. Suppose that you have made primary measurements of quantities and , and want to get the best value and error for some derived quantity .
Case 1: For addition or subtraction of measured quantities the absolute error of the sum or difference is the ‘addition in quadrature’ of the absolute errors of the measured quantities; if
$$\Delta S=\sqrt{(\Delta A)^2+(\Delta B)^2}$$This rule, rather than the simple linear addition of the individual absolute errors, incorporates the fact that random errors (equally likely to be positive or negative) partly cancel each other in the error
Case 2: For multiplication or division of measured quantities the relative error of the product or quotient is the ‘addition in quadrature’ of the relative errors of the measured quantities; if or
$$\Large \frac{\Delta S}{S}=\sqrt{(\frac{\Delta A}{A})^2+(\frac{\Delta B}{B})^2}$$Due to the quadratic addition in (E.6) and (E.7) one can often neglect the smaller of two errors. For example, if the error of is 2 (in arbitrary units) and the error of B is , then
the error of is .
Thus, if you don’t want to be more precise in your error estimate than ~12% (which in most cases is sufficient, since errors are an estimate and not a precise calculation) you can simply neglect the error in B, although it is is 1/2 of the error of A.
Case 3: When you're interested in a measured quantity that must be raised to the n-th power in a formula ( doesn't have to be an integer, and it can be positive or negative), viz., you're interested in , the relative error of the quantity is the relative error of multiplied by the magnitude of the exponent $$\Large \frac{\Delta S}{S}=|n|\times \frac{\Delta A}{A}$$ As an example for the application of (E.8) to an actual physics problem, let's take the formula relating the period and length of a pendulum:
$$T=2 \pi \Large \sqrt{\frac{L}{g}}$$where \(g=9.81 m/s^2\) is the constant acceleration of gravity. We rewrite (E.9a) as
$$T=\left({\Large \frac{2 \pi}{g^{1/2}}} \right) L^{1/2}$$to put all the constants between the parentheses. We now identify \(S\) in (E.8) with and identify with . Therefore, we identify with and see that for our example. Since appears in (E.8) [the vertical bars around mean “absolute value”], only the magnitude of is important, so we don't have to worry about the sign of : we get the same result whether the exponent is positive or negative, as long as it's in our example. If we're interested in evaluating , we see from (E.3) that the constant , which in our case equals , “drops out”.
Therefore, we find that . This example should help you apply (E.8) to cases having values of the exponent different from the particular value used in this example.
Often you will be asked to plot results obtained in the lab and to find certain quantities from the slope of the graph. In this course you will always plot the quantities against one another in such a way that you end up with a linear plot. It is important to have error bars on the graph that show the uncertainty in the quantities you are plotting and help you to estimate the error in the slope (and, maybe, the intercept, too) of the graph, and hence the error(s) in the quantity(ies) you are trying to determine.
To demonstrate this we are going to consider an example that you will study in detail later in the course, the simple pendulum. A simple pendulum consists of a weight suspended from a fixed point by a string of length . The weight swings about a fixed point. At a given time, is the angle that the string makes with to the vertical (direction of the acceleration of gravity).
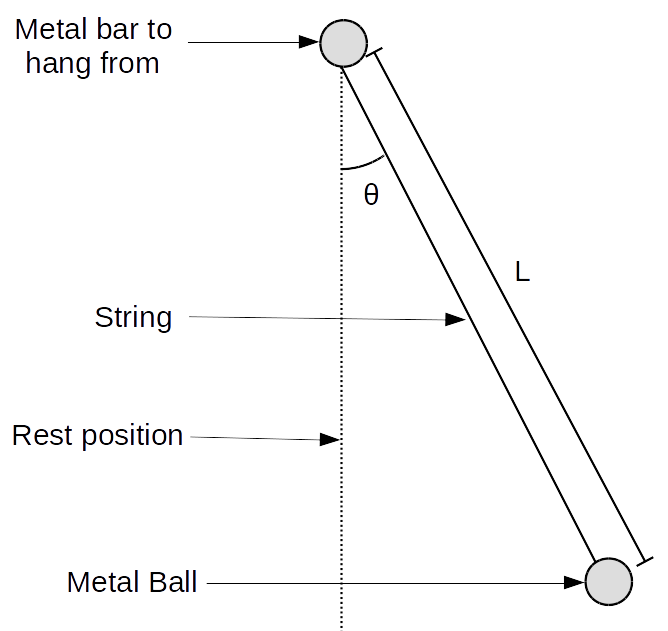
The period of this motion is defined as the time necessary for the weight to swing back and forth once. In your study of oscillations, you will learn that an approximate relation between the period and length of the pendulum is given by , Eq. (E.9a), where m/s is the constant acceleration of gravity. The derivation of Eq. (E.9a) uses the assumption that the angle is small.
An experiment with the simple pendulum: Things one would measure
By measuring \(T\), the period of oscillation of the pendulum, as a function of , the square-root of the length of the string, one can determine \(g\), the acceleration of gravity. Note that the previous sentence establishes the length (actually, its square-root) as the independent variable (what one sets initially) and as the dependent variable (the quantity that depends on what length is chosen). Indeed, this is the way Eqs. (E.9a,b) are written: as a function of .
To produce a “straight-line” (linear) graph at the end of this document, we'll rewrite Eq. (E.9) a third way, viz., we'll square both sides of Eq. (E.9b):
$$T^2= {\Large \frac{(2 \pi)^2}{g}} L$$The dependent variable in Eq. (E.9c) depends linearly on the independent variable . The factor is a constant, and is a parameter that can be determined, along with its uncertainty, from the measurement of and and their uncertainties.
The video shows you how to measure the different quantities that are important in the experiment: , the angle that makes with the vertical before the pendulum is released, and . Note that to minimize random errors, one should measure each several times (and from those data determine a mean value and its uncertainty) and measure the length of time needed for, say, 10 oscillations so that we may determine the period from 10 swings of the pendulum rather than from just one swing. Notice that the measurement in the video uses the computer as a stopwatch that must be started and stopped “by hand” based on “eyeball + brain” determinations of the angular position of the pendulum. This introduces measurement uncertainty into the time measurement, which is fractionally less if one measures for 10 oscillations than “directly” from one oscillation. We will be using the computer frequently in this course to assist us in making measurements and recording data.
Suppose that we measure the length of the string 5 times and find the following 5 values:
| Measurement No. | L [cm] |
|---|---|
| 1 | 56.4 |
| 2 | 56.6 |
| 3 | 56.7 |
| 4 | 56.6 |
| 5 | 56.5 |
Finding the average value is straightforward:
cm (to the precision of 2 figures beyond the decimal point as is warranted by the error found below)
You find the (absolute) error in the average using equation (E.5b):
= 0.05 cm
So we can say that our measured value for is cm. (The relative error is .)
We ask you to do a similar calculation for a different set of numbers in the online lab quiz to see that you understand how to do it.
Error in the period
If we measure the time for 10 oscillations we can find the time for one oscillation simply by dividing by 10. Now we need to make an estimate of the error.
First you need to estimate the error in your measurement. How accurately do you think you can press the button to tell the computer when to start and stop the measurement? Let's say that you think you can press the button within 0.2 seconds of either the start or the stop of the measurement. You need to account for the errors at the start and the stop, but as we discussed earlier, because these errors are random they add in quadrature so you can say that
s
Now we find the error in T by dividing by 10
s
So you can see it was a good idea to measure several periods instead of one, we get a much more precise result. Maybe you'd like to think about why we don't measure 100 oscillations. (Because you'd get bored is only part of the answer!)
Making a plot of our data
Now we have some idea of the uncertainty in our measurements we can look at some data and try to see if they match the formula we have reason to expect is valid. What we would do is, for a fixed angle , to change the length of the string and, for each value of , to find the corresponding oscillation period . Take a look at the following set of data taken by one of our TAs:
| L[cm ] | ΔL [cm] | 10T[s] | T[s] | ΔT[s] | T2[s2] | ΔT2[s2] |
|---|---|---|---|---|---|---|
| 10.6 | 0.1 | 6.2 | 0.62 | 0.028 | 0.38 | 0.03 |
| 21.9 | 0.1 | 9.1 | 0.91 | 0.028 | 0.82 | 0.05 |
| 33.2 | 0.1 | 11.6 | 1.16 | 0.028 | 1.34 | 0.06 |
| 40.5 | 0.1 | 12.8 | 1.28 | 0.028 | 1.65 | 0.07 |
| 48.4 | 0.1 | 14.0 | 1.40 | 0.028 | 1.95 | 0.08 |
| 61.6 | 0.1 | 15.8 | 1.48 | 0.028 | 2.48 | 0.09 |
| 73.1 | 0.1 | 17.4 | 1.74 | 0.028 | 3.01 | 0.10 |
| 81.4 | 0.1 | 18.1 | 1.81 | 0.028 | 3.27 | 0.11 |
| 89.6 | 0.1 | 19.4 | 1.91 | 0.082 | 3.75 | 0.08 |
You should understand from what is presented above how we got the first 5 columns. The rest of the table shows the necessary transformation of the data into the quantities we need to plot. Because of Eq. (E.9c) and the discussion around it, you already know why we need to calculate : We expect to get a straight line if we plot (-axis) vs. (-axis). This also means we need to know what is the uncertainty, , in so that we may draw vertical error bars (error bars for the dependent variable are “vertical”, i.e., parallel to the -axis) on the graph. How to calculate is one of the problems in the online lab quiz. Not to worry: we ask you to do it for only one set of numbers, and we'll guide you through the formulas. We've already filled in the numbers for the data in the table. We're assuming that the horizontal error bars (the uncertainties in the dependent variable along the -axis) are all the same.
To make the graph from the data you'll make your first use of the plotting tool we will be using throughout this course. The tool is hosted by our IntroLabs server and has a webpage interface; when you enter your data and then click “submit” it will make the graph in a new tab. This makes it easy to change something and get another graph if you made a mistake. After typing in labels and units for the -axis and -axis, you should enter the values as your “” values in the table and your values as your “” values in the table. According to the Eq. (E.9c) that we are testing, when , , so you should check the box that asks you if the fit must go through (0,0), viz., “through the origin”. Enter the appropriate errors in the +/- boxes and choose “errors in x and y”. Click “submit” when you are done.
If you entered everything right then on your new tab you should see something that looks like this:

It's evident that data are quite linear when plotted this way, which gives us an indication that our formula has the right algebraic form. Notice that you can only barely see the horizontal error bars; they are much smaller than the vertical error bars.
Maybe you would like to try plotting \(T \) directly against \(L \) on a piece of graph paper to see what this graph looks like. You can't use the plotting tool because \(T \) vs. \(L \) will not give a linear graph.
Warning: The plotting tool works only for linear graphs of the form , where is the slope, and is the -intercept. If you check the box to force the fit (which we call the “constrained fit”) to go through the origin (0,0), you don't get a value for because it is zero. If you don't check the box, the program will calculate a value for and its uncertainty , and it will calculate a value for and its uncertainty .
The program that goes to work when you push the “submit” button performs a least-squares fit to the data . This means that it calculates for each data point the square of the difference between that data point and the line trying to pass through it. It then adds up all these “squares” and uses this number to determine how good the fit is. Instructed by the program, the computer tries to find the line that gives the smallest sum of all the squares and calls this the line of best fit. It draws this line on the graph and calls it “y=a*x” (a times x). Because you checked the box, it does not give you a value for because it is “constrained” to be zero. It does give you the value of the slope and the computed estimate for its uncertainty . (These values are printed out in the upper-left corner of the plot. The first number is , and the second number, the one after the +/- symbol, is .) The value the program gives for depends on the experimental uncertainties you enter for the data points, which determine how to the different data points are “weighted” in the fit.
If you do not check the box, and, therefore, do not force the fit to go through the origin (0,0), the plotting program will find a value for the intercept and its uncertainty , and they will be also be printed out in the upper-left corner of the plot.
Another technique you can use to estimate the error in the slope is to draw “max” and “min” lines. Here we use our “eyeball + brain” judgment to draw two lines, one that has the maximum slope that seems reasonable, the “max” line, and another that has the smallest slope that seems reasonable, the “min” line. We do NOT use the computer to draw these lines, and normally we do the judgment process leading to our choice of suitable “max” and “min” lines on paper, but you can do it more quickly and simply by holding a clear plastic ruler up to the screen of the computer monitor to decide where you think the max and min lines should be. But please DON'T draw on the screen of the computer monitor! The surface exposed to you is made of soft plastic and can easily be scratched permanently. Such scratches distort the image being presented on the screen. A line is reasonable if it just passes within most of the error bars. You then just take two convenient points on the line, and find the change in the dependent variable “” over the change in the independent variable “” to calculate the slope. Doing this to work out the slope of both lines, max and min, gives you an estimate for the uncertainty in the slope. (Note that if you decide not to force your eyeball + brain max and min lines to go through the origin (0,0), you also get an estimate for the uncertainty in the intercept. This only makes sense if you did not “check the box” when using the plotting tool to do the linear fit.)
The example we show next uses the same pendulum data presented above, but this time you should notice that the plot has been made “the other way”, viz., as (cm) (on the -axis) versus () (on the -axis). You could do this yourself by entering the data into the plotting tool in the proper way. A consequence of plotting the data this way is that the large error bars – those for – are now in the horizontal direction, not in the vertical direction as they were for the first plot. This doesn't affect how we draw the “max” and “min” lines, however. You'll notice that the max and min lines for the present case, which appear in black on the computer screen versus green for the “best fit” line obtained with the plotting tool and versus red for the “error bars”, both pass through the origin, as they should when one is comparing them to a constrained fit obtained by “checking the box”, and they both pass through nearly all the “large” error bars, the horizontal ones. Your eyeball + brain choice of suitable max and min lines would undoubtedly be slightly different from those shown in the figure, but they should be relatively close to these. For the ones shown in the plot, which are reasonable choices, you may calculate yourself that the max line has a slope of about cm/s, and the min line has slope of about cm/s. Therefore if you used this max-min method you would conclude that the value of the slope is 24.4 0.7 cm/s, as compared to the computers estimate of 24.41 0.16 cm/s.

We may now use these values for the slope and its uncertainty to calculate values for the acceleration due to gravity, , and its uncertainty, . Remember from Eq. (E.9c) that . This means that the slope (labeled as by the plotting tool) of our graph should be equal to . To get we should multiply the slope by , and we should also divide by 100 to convert from cm/s to m/s so that we're using standard SI units. Using the plotting-tool's best values from the constrained, linear fit for and its uncertainty gives
\(g=9.64 \pm 0.06 m/s^2\).
If, instead, we use our max-min eyeball + brain estimate for the uncertainty \(\Delta a\) along with the plotting-tool's best value for the constrained linear fit for \(a\), we get
\(g=9.64 \pm 0.28 m/s^2\).
Aside: Because both plots use (constrained) linear fits to the same set of experimental data, the slope of the best-fit line for the first plot, (s) (on the -axis) versus (cm) (on the -axis), must be related in some way to the slope of the best-fit line for the second plot, (cm) (on the -axis) versus () (on the -axis). A physicist would say that since the two linear graphs are based on the same data, they should carry the same “physical information”. Can you figure out how these slopes are related? Reading the next few paragraphs carefully, and following along by doing the calculations yourself, you should be able to figure this out.
Since the accepted value for \(g\) at the surface of the earth is \( g= 9.81 m/s^2 \), which falls within the range we found using the max-min method, we may say, based on that estimate for the uncertainty in \(g\), that our experiment is consistent with the equation (E.9) we “tested” with our experimental data. If we used the computer's estimate for , however, we would conclude that the data are inconsistent with the accepted value for \(g\). Loosely, we might say that the computer “thinks” the uncertainty in the slope of the experimental data is smaller than what we estimate by eyeball + brain. Though our eyeball + brain method is not “digital-numerical/computational”, it is still a reasonable “analog computational” (neuroscientific, if you like) estimate, and it is much easier to do it than it is to write a computer program to do the linear fit. You should always use such an eyeball + brain method first to provide a ballpark estimate for the uncertainty. If the data seem good enough to warrant the extra effort, you should use then use a digital-numerical/computational method to get a more careful estimate of the uncertainty. If the latter wildly disagrees with the former, it probably means you made a mistake in doing the digital-numerical calculation.
This demonstrates why we need to be careful about the methods we use to estimate uncertainties; depending on the data one method may be better than the other. Generally it is safer to take the larger of the two estimates, but these kinds of judgments are the kinds of things it will be useful to discuss with your TA when you are doing experiments and analyzing your data. Another thing to bear in mind is that we were quite careful here about trying to eliminate random errors; if systematic error were present then our methods would not have done very much to help. This is always something we should bear in mind when comparing values we measure in the lab to “accepted” values. We also need to think carefully about simplifying assumptions we make. For example, we assumed that the pendulum did not “slow down or speed up” (i.e., have its oscillation period increase or decrease) at all during the 10 swings we measured. Additionally, there are approximations used in the derivation of the equation (E.9) were test here, so that equation is not “exact”. The period of a real (free) pendulum does change as its swings gt smaller and smaller from, e.g., air friction.
Bearing these things in mind, an important, general point to make is that we should not be surprised if something we measure in the lab does not match exactly with what we might expect. When things don't seem to work we should think hard about why, but we must never modify our data to make a result match our expectations! This “fudging the data” is not acceptable scientific practice, and indeed many famous discoveries would never have been made if scientists did this kind of thing. Unfortunately, sometimes scientists have done this (though it is rare in physics), and when it happens it can set science back a long way and ruin the careers of those who do it. A prominent example in physics from 2022 is Jan Hendrik Schön. He was fired from his job in a prominent research laboratory and then had his Ph.D. degree revoked by the University of Konstanz that had granted it to him. Schoen's scientific career was ruined by his fraudulent actions, which amounted to cheating.
Hovering over these bubbles will make a footnote pop up. Gray footnotes are citations and links to outside references.
Blue footnotes are discussions of general physics material that would break up the flow of explanation to include directly. These can be important subtleties, advanced material, historical asides, hints for questions, etc.
Yellow footnotes are details about experimental procedure or analysis. These can be reminders about how to use equipment, explanations of how to get good results, troubleshooting tips, or clarifications on details of frequent confusion.
For a review of electric field, see Katz, Chapter 24 or Ginacoli, Chapter 21.